
On this page
Google's Gemma 2 9B is a recently released open-source language model that has garnered significant attention in our community. This lightweight model, is part of the Gemma family of models developed by Google. Despite its relatively small size, Gemma 2 9B has demonstrated impressive capabilities and performance that feels comparable or even superior to larger models like GPT-3.5. It boasts open weights that enable deployment in resource-constrained environments such as phones, PCs, or on-premises clouds. Gemma 2 falls easily into the category of a Small Language Models (SLMs) which we seem to be talking a lot about lately.
Mozilla's Llamafile
Is a groundbreaking tool that has revolutionized the way we distribute and run Large or Small Language Models. This innovative solution collapses the complexity of LLM/SLM deployment into a single-file executable, making them significantly more accessible to both developers and end users.
 Mozilla-Ocho
Mozilla-OchoThanks to the author Justine Tunney, llamafile ingeniously combines llama.cpp with her own Cosmopolitan Libc. It enables llamafile to execute AI models without the need for Python 🐍 or any other software installation. Seriously, .llamafiles can run on six OSes (macOS, Windows, Linux, FreeBSD, OpenBSD, and NetBSD) out of the box and on different architectures such as ARM64 and AMD64. In a single file! This creates what are called Actually Portable Executables which is a dream for many including Justine.
The result, a super simple deployment process that democratizes access to powerful AI models, paving the way for more widespread adoption and experimentation for applied AI practitioners like us. Llamafile's project includes pre-built files for models such as LLaVA 1.5, Mistral 7B Instruct, and even Phi 3 Mini 4K Instruct. So it was no surprise to see Justine showcase llamafile with Google's new Gemma 2 family.
I've just uploaded llamafiles for Google's new Gemma2 language model. This is the 27B model that folks have been saying is better than 70B and 104B models like LLaMA3 and Command-R+. People are even saying it's better than the original GPT4! Now you can run it air-gapped on your… pic.twitter.com/gq4bWFlgmS
— Justine Tunney (@JustineTunney) July 2, 2024
Read the full 🧵 thread above. It contains accurate insights into Google's miss on the model's licensing. We all saw this week where Stability had to walk back their restrictive license in their new flagship SD3 model? More of this please.
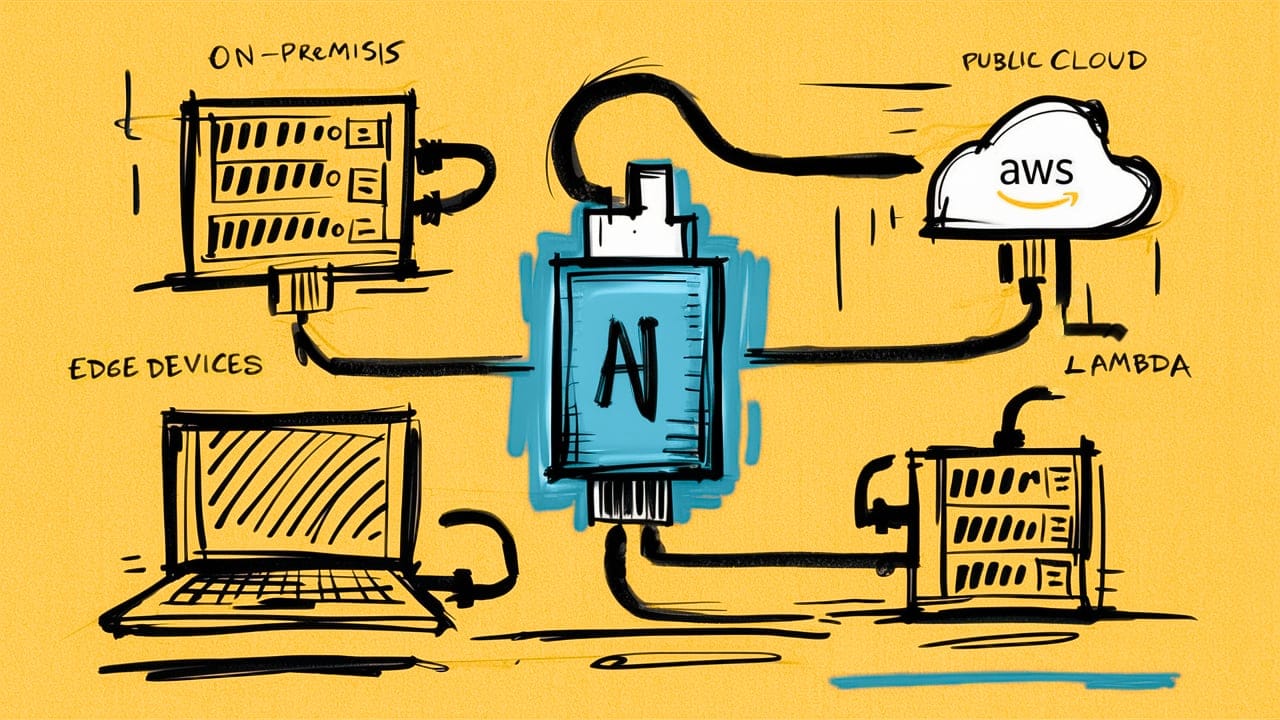
Slim Models on Fat Lambdas
So right away I was nerd sniped. I've tried a few times to deploy AI inference to AWS Lambda after seeing others do the same with Mistral or LLama 2. But the general findings have been lackluster. I was also curious if llamafile's new single file deployment along with a bit of grit & determination from yours truly might yields new results given llamafile's recent perf optimizations.
I will admit, I have been hesitant and sometimes downright dismissive on the topic of running models locally. Cheap token-based cloud inference feels more "serverless" to me. But with so many SLMs being released lately, an itch to try LoRA in some capacity, and finally a new M3 Mac that flies 🏃♂️ with llamafile - I hope to change and find more use cases for local AI.
Quick note ☝️, with that caveat out of the way, here is how I approached the Lambda architecture choices. First, I wanted to only use JavaScript and the Shell programming languages. The goal here is to help democratize AI just as llamafile is doing. Sorry again Python. Second, the AWS Lambda project would assume the following setup, tool usage, and constraints.
- Use of the AWS SAM CLI for fast and easy serverless deployments.
- Function URLs for built-in HTTPS proxy to the llamafile's API server running behind the powerful Lambda Web Adapter, a Rust proxy.
- The Arm/Graviton2 architecture for highest performance and cost.
- As much memory (10GB) and vCPUs (6) Lambda can handle.
- The container image deployment package for up to (10GB) of storage.
After several hard lessons and some intense problem solving, it worked out pretty well. I'll cover those learnings in the next section. Everything is also wrapped up in this GitHub repository which you can deploy to your own AWS account. You can even change a few variables and deploy other llamafile models.
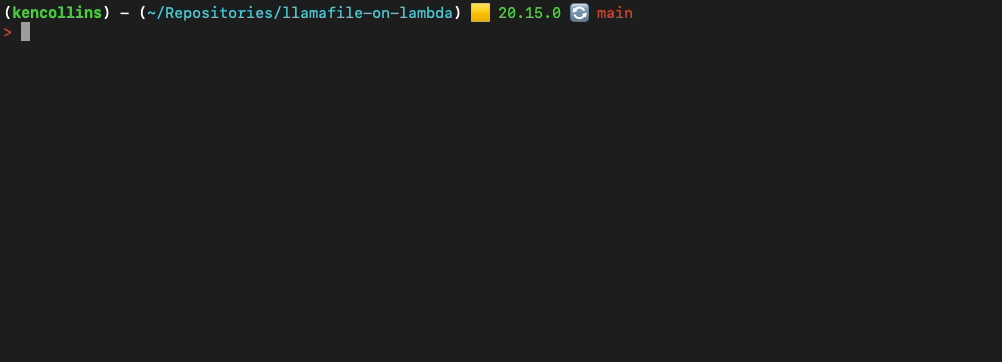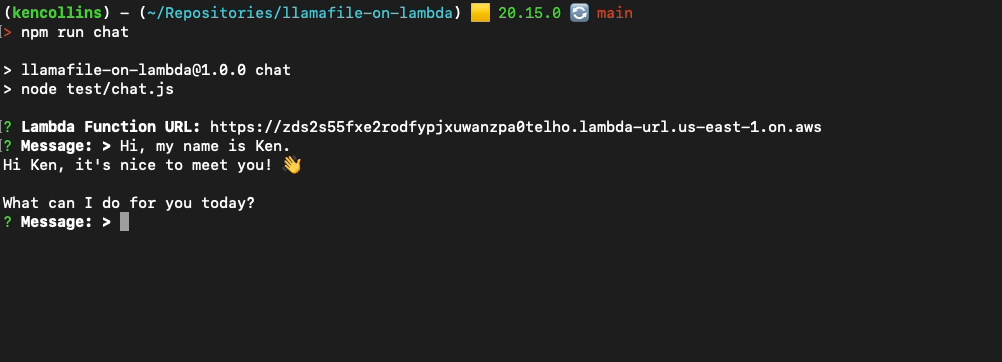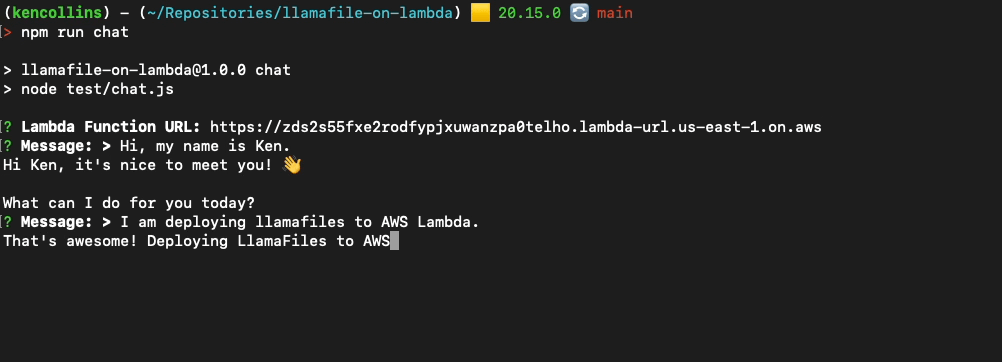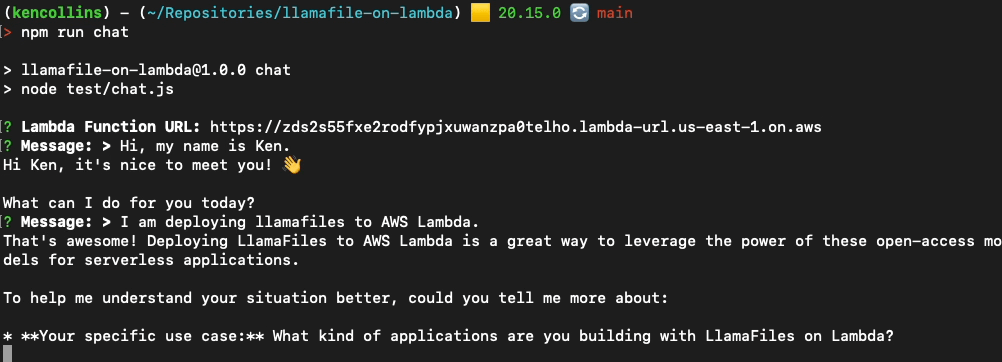
metaskillsHere is an example of me chatting with the Gemma 2 model using OpenAI's JavaScript API and Inquirer.js by running npm run chat in the project.
Learning & Lessons
The first and largest hurdle I ran into is the Lambda execution environment's 10 second init lifecycle. The llamafile API server by default does a model warm up which can take around 20-40 seconds.
The warmup pull request was implemented. Thank you Justine. We also removed patches from our demo project on GitHub.
Thankfully, Justine has been an amazing open-source maintainer and is going to allow the llamafile server to bypass the warmup phase so there can be distinct liveliness and readiness events for containerized workloads. The Dockerfile in our project patches llamafile till this behavior is applied upstream. Follow along here:
Mozilla-OchoThe bad news is that the warmup still has to happen. If you were to start a chat session or invoke your function via an API, the first response will take that performance hit. However, invokes to the same function will be much faster.
Small & Quantized
So with the 10GB container image constraint, you are going to be limited to SLMs under that size with AWS Lambda. Even then, Lambda is going to need a highly quantized variant. In our test today I used Gemma 2 9B Q2 from Justine's Hugging Face page. This file is around 3.8GB.

I tested this model up to Q6 and nothing in between felt good. I'm not sure if other model variants such as Phi 3 Mini 4K Instruct or LLaVA would perform better at different levels of quantization. I would very much like to hear from others if you do play around with this project. My guess is the Lambda virtualized environment is just too bare bones to get any better performance. For now, I'll keep virtual GPU support on my AWS Wishlist.
Tokens Per Minute?
While playing around, I came up with ~200 tokens per minute on longer responses to a warmed up model. This is likely going to be very different for other models and each model's quantization. Your mileage may vary and I'd love to hear what works for others.
Memory & Lambda vCPUs
I found that anything less than 6 vCPUs sacrificed performance. Cutting it down to 3 vs 6 vCPUs lost around 40% of performance. What sucked is that no matter what... and I mean no matter what, I could not get Lambda to use more than ~3900MB of memory. The --mmap config with llamafile was no help because you can not change ulimits on AWS Lambda.
Llamafile Configs & Gotchas
Here are a few llamafile configs I found critical when starting the API server. You can find these in the CMD script in the project link above. Each is followed by a short description.
--fastI could not measure any perf gain with this on or off.--threadsAlways set these to the same value asnproc. The default for llamafile is nproc/2 which has about a 30% performance hit.--nobrowserLocally starting the llamafile API server will open a browser window to the llama.cpp page. Not needed on servers.--logdisableMoves some logging back to STDOUT and avoids Lambda's read-only filesystem.
To keep llamafile from installing ape into your home directory, install it ahead of time in your Dockerfile. Lambda is a read-only filesystem, so a lazy install will fail.
That's it! Hope y'all found this post useful and please do let me know if you explore AWS Lambda and Llamafile more. I would love to hear what other folks are doing with SLMs. Please feel free to message or chat with me on LinkedIn or Twitter/X.



